Introduction
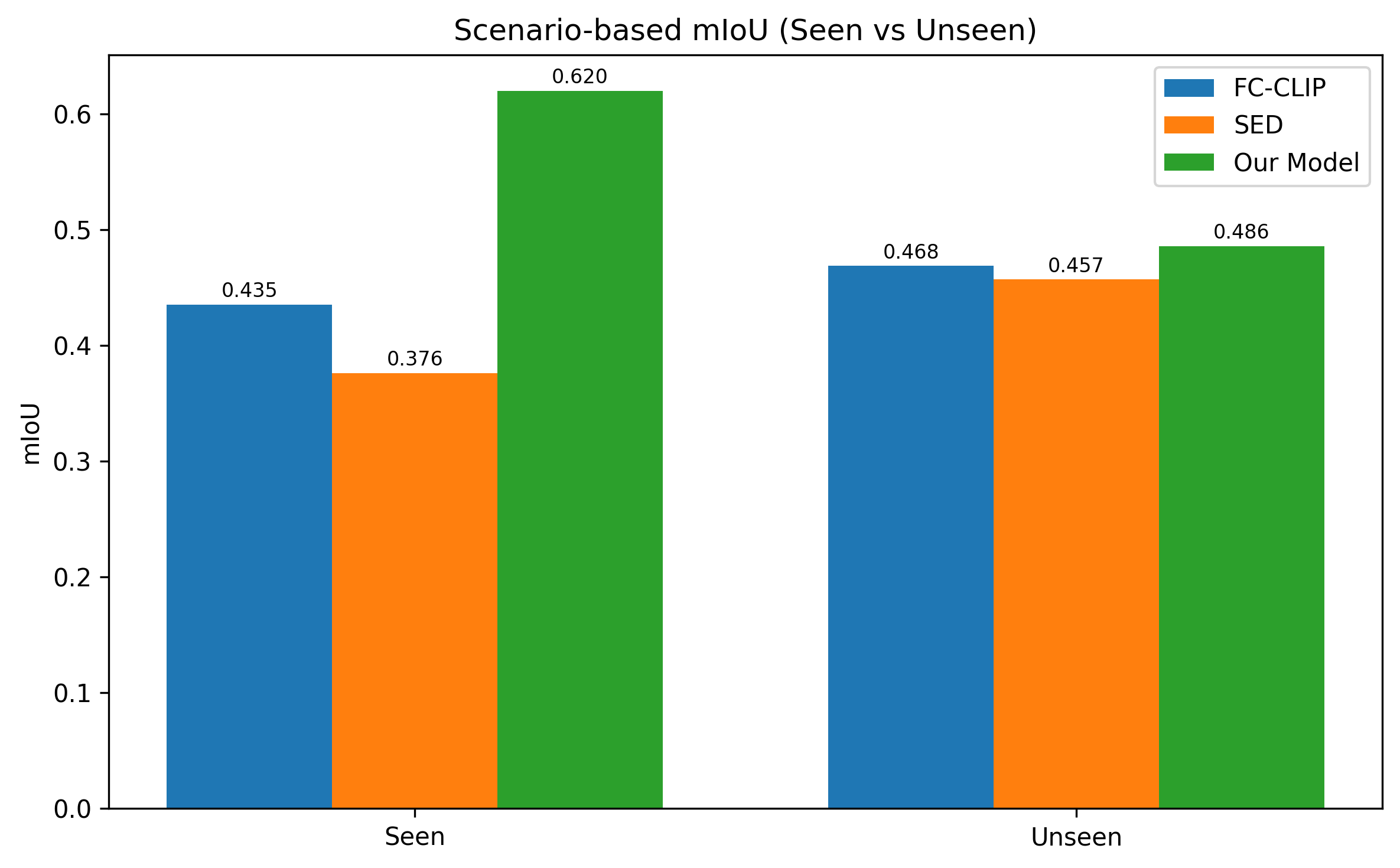
We build a depth-aware open-vocabulary semantic segmentation pipeline for adverse-condition urban scenes (night, rain, fog). It augments a frozen CLIP–ConvNeXt backbone with a monocular depth prior and a geometry-conditioned text query decoder, trained in a parameter-efficient regime. On 50 ACDC adverse-condition frames, our model reaches mIoU 0.620 / 0.486 on Seen / Unseen Cityscapes classes — beating FC-CLIP (0.435 / 0.468) and SED (0.376 / 0.457).

Motivation
Zero-shot vision–language segmenters work well on clean scenes but fail in the cases that matter most for mobility and safety analysis: nighttime, rain, glare, occlusion. Symptoms are predictable — boundaries blur into shadow, small but safety-critical classes (signs, poles) vanish, and large regions collapse onto a single background label.
Our hypothesis: under adverse conditions texture alone is a weak cue, but a geometric prior — ground plane, vertical surfaces, near/far — survives illumination loss. The challenge is to inject that prior into a frozen open-vocabulary backbone without sacrificing zero-shot text alignment and without the prohibitive cost of full-parameter VLM training.